Measuring the Spread of Ideas through the Physical Review
With so many scientific journals available online, researchers can explore linkages among papers and networks of scientific influence in unprecedented detail. Now a team of researchers offers a new take on this kind of analysis. They report a method for scrutinizing collections of papers to identify “memes”—words or phrases that capture specific scientific concepts and gain wide acceptance in their disciplines. The researchers say that their method could be a quantitative and objective tool for studying the emergence and evolution of scientific ideas.
Since the mid 1960s, researchers have studied the citation links among scientific papers to investigate the influence, interconnectedness, and “impact factor” of authors and papers. But Tobias Kuhn of the Swiss Federal Institute of Technology (ETH) in Zurich and his colleagues point out that these methods do not allow direct study of the spread of the intellectual content of those papers through the scientific community.
To explore the emergence of scientific ideas, Kuhn and his colleagues wanted to find a way to scour the literature for words or phrases representing significant scientific concepts, but at the same time distinguish them from common terms, such as “experiment.” They call these words or phrases “memes,” using the name originally proposed by evolutionary biologist Richard Dawkins for noteworthy intellectual objects—a religion or a brand of politics, for example. According to Dawkins, memes can thrive or dissipate as they disperse through a human culture [1].
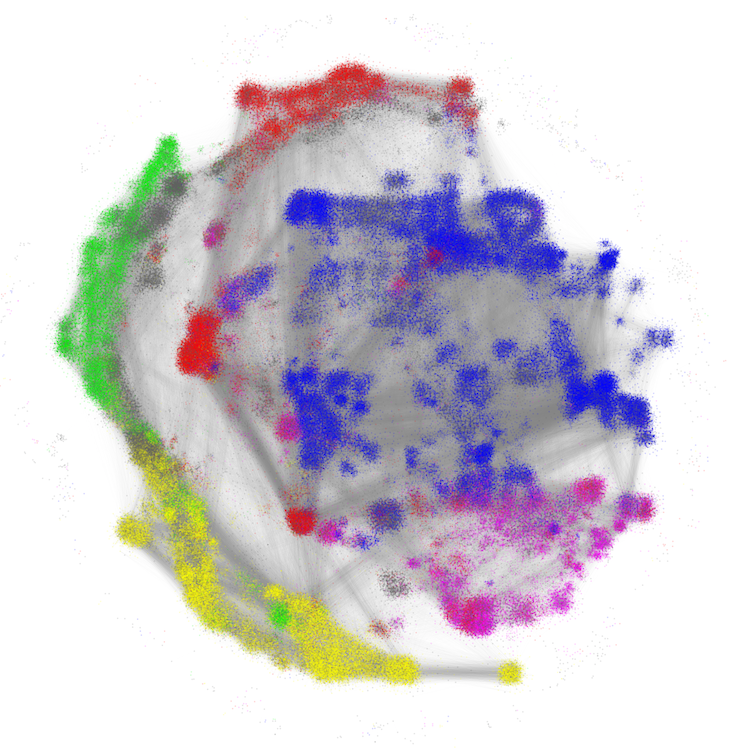
In their search for memes, the team focused on the nearly half million titles and abstracts in the American Physical Society’s Physical Review archive from 1893 to 2009. Using standard software, they constructed a citation network that depicted the dataset as a cloud of points—each point representing a single publication, and clusters of points indicating papers with many citations in common. Large-scale clusters in this picture correspond to the subareas of physics covered by each Physical Review journal, with connections between the clusters reflecting interdisciplinary crossover.
Through sheer computing power, Kuhn and his colleagues then searched through this APS database for every possible repeated sequence of words, called an -gram. Some of these—for example, “of” or “of the”—appeared with great frequency, but clearly aren’t memes. So the team defined a statistical measure, which they call the propagation score, for each -gram. A high propagation score corresponds to an -gram that closely tracks the citation pattern, that is, it shows up preferentially in papers that cite other papers containing the same -gram. Common words like “of” have a low propagation score.
The team then defined the overall “meme score” of an -gram as its propagation score multiplied by the frequency with which it appears in the database. This procedure gave similar meme scores to terms such as “quantum,” “graphene,” and “traffic flow,” even though their frequencies differed by a factor of more than a hundred. They conducted a similar analysis on two other databases, the Web of Science, with more than million papers, and PubMed, with about half a million papers. The researchers mapped the distribution of -grams on two-dimensional plots with propagation score as the horizontal axis and frequency as the vertical axis. In these plots, lines of constant meme score run from upper left to lower right. The researchers found that for each dataset, a similar distribution of -grams filled the region below and to the left of the maximum meme score, despite the differences in size and subject matter of the three databases.
But did high-scoring -grams truly represent scientific memes? The 50 terms from the APS archive with the highest propagation scores included many plausible meme candidates, such as “loop quantum cosmology” (#1) and “carbon nanotubes” (#6), as well as several chemical formulas, including (#7; a well-known superconductor). To judge the significance of these terms, the researchers checked to see if Wikipedia had entries for them and also enlisted two physics graduate students to assess the terms’ significance. A majority of the top-50 terms passed both tests.
Alexander Petersen of the Institutions, Markets, Technologies (IMT) Institute of Advanced Studies in Lucca, Italy, says he is impressed that this “simple yet powerful” method finds both extremely rare memes as well as fairly common ones. He thinks that the meme model demonstrated by Kuhn and his colleagues offers a “fruitful starting point” for deeper analysis of the spread of scientific ideas, patterned on principles adapted from the processes of genetic inheritance.
This research is published in Physical Review X.
–David Lindley
David Lindley is a freelance science writer in Alexandria, Virginia.