Tobias Toll
Viewpoint
Of Gluons and Fireflies
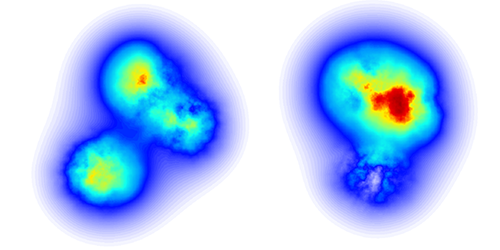
Improved models of gluon fluctuations within protons have been developed and applied to particle collision data, pointing to strong gluon fluctuations at high energies. Read More »
Improved models of gluon fluctuations within protons have been developed and applied to particle collision data, pointing to strong gluon fluctuations at high energies. Read More »